
Introduction to Language Server Index Format (LSIF)
The Language Server Index Format (LSIF) is a specification designed to enable language servers to provide rich indexing and semantic analysis of source code, which enhances the functionality of code editors and Integrated Development Environments (IDEs). LSIF is primarily aimed at facilitating the transfer of source code metadata between different services, providing an efficient way for IDEs and version control systems to analyze and index large codebases. It offers a standardized approach for integrating various language features, improving the developer experience and workflow, by making advanced code navigation, code intelligence, and semantic understanding available in multiple environments.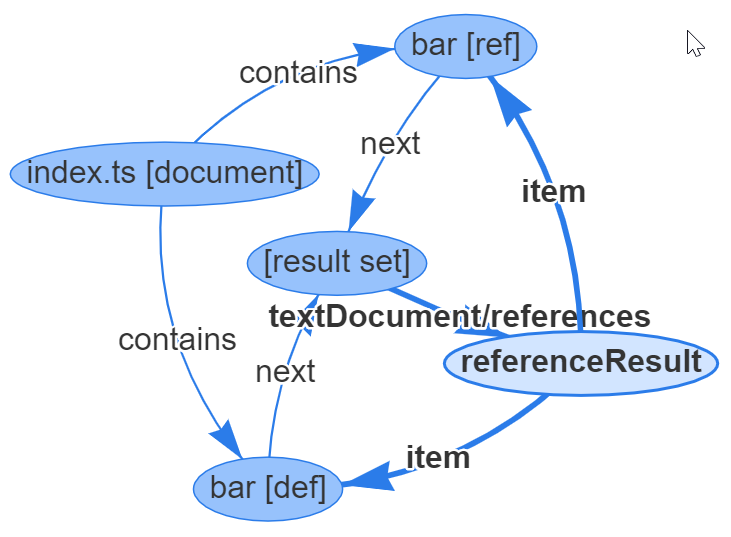
History and Development of LSIF
LSIF was first introduced in 2019 by Dan Adler, a key figure in its development, as a response to the increasing need for effective code indexing tools that could integrate with a variety of IDEs, language servers, and tools within the software development lifecycle. The goal of LSIF is to provide a platform-independent, lightweight format that would enable language servers to share information about code structure, symbols, references, and more without being bound to any particular programming language or toolset. The development of LSIF was driven by the needs of the developer community, especially those working with large-scale projects that span multiple languages or rely heavily on modular codebases.
The LSIF specification was primarily developed under the influence of Sourcegraph, a company that specializes in providing code search and intelligence platforms for large codebases. Sourcegraph’s contributions to LSIF were instrumental in shaping its focus on scalability and interoperability.
Key Features of LSIF
LSIF provides several key features that make it a valuable tool for code analysis and indexing. These features aim to enhance the developer’s productivity by providing more efficient ways to search and interact with code.
1. Comments Support
One of the core features of LSIF is its support for comments. This feature allows language servers to include detailed information about comments within the codebase. Since comments are essential for understanding code logic and providing context, this capability ensures that the indexing process captures important non-executable information as well.
2. Line Comments
LSIF also supports line comments (e.g., // in languages like C, C++, and JavaScript), enabling the indexing of individual lines of code. This facilitates enhanced search capabilities, such as searching for comments or annotations within specific lines of a file, improving the discoverability of relevant sections of code.
3. Semantic Indentation
However, semantic indentation is not currently supported in LSIF. This means that while LSIF can index the structure of code, it does not capture or analyze how the indentation of a line might relate to the code’s semantics. This limitation does not significantly affect basic code navigation features but may limit some advanced code formatting and refactoring functionalities that rely on semantic indentation.
Structure of LSIF Files
LSIF files are typically represented in a JSON format, which makes them easily readable and extensible. The structure of an LSIF file includes a variety of components, such as:
- Symbols: Information about identifiers, variables, classes, methods, and other code elements that are indexed for easy lookup.
- Definitions: References to the original definitions of symbols, enabling features like “Go to definition” or “Find references.”
- References: Data about where symbols are used throughout the code, providing insight into code dependencies.
- Diagnostics: Information related to any code issues, warnings, or errors, allowing for better error detection and resolution within the development environment.
By structuring data in a consistent way, LSIF ensures that developers and tools can efficiently interpret and use the code metadata without relying on the intricacies of specific programming languages or IDEs.
LSIF in Practice
The practical use of LSIF can be seen in its ability to power a variety of language services and features that improve code analysis and interaction. One of the most common use cases is its integration with code editors and IDEs, which can use LSIF to provide advanced features like:
- Code Autocompletion: Based on indexed symbols and definitions, LSIF helps language servers offer predictive autocompletion of code.
- Code Navigation: LSIF allows users to quickly navigate to definitions, references, and symbols within a codebase, reducing the time spent searching for specific code segments.
- Code Search: By providing a rich set of metadata, LSIF enables more efficient searching of code across large repositories, including searching for references, comments, and other key elements.
- Error Detection: By integrating with diagnostics information, LSIF enables tools to detect issues, warnings, and errors in code early in the development process.
These capabilities enable developers to write, refactor, and maintain code more efficiently, particularly in large, complex codebases.
LSIF’s Role in Open-Source Software
LSIF is an open-source initiative, meaning it is available for anyone to use, modify, or contribute to. Its openness is one of the key factors that have led to its adoption across a wide variety of programming languages and projects. While the format itself is language-agnostic, its adoption has been particularly beneficial in environments where multiple programming languages are used together, such as large enterprise software systems or open-source projects with diverse contributors.
The open-source nature of LSIF has allowed it to gain widespread traction in the software development community. Sourcegraph, for example, has actively promoted LSIF as part of its code intelligence platform, which relies on LSIF-formatted data to provide features like global code search and code intelligence. The widespread support for LSIF in many IDEs and language servers further demonstrates its utility in the modern software development workflow.
GitHub and LSIF
As a part of the wider push to improve developer tools, LSIF has found support on platforms like GitHub. GitHub hosts a variety of repositories related to LSIF, and the platform uses LSIF data to power its own search and code navigation features. By adopting LSIF, GitHub is able to offer richer code search and navigation experiences to developers working with open-source projects.
GitHub also supports the LSIF format through GitHub Repositories, where developers can find issues related to LSIF (e.g., version 4.0 of the LSIF specification), as well as updates and discussions regarding the LSIF project. GitHub’s integration with LSIF serves as an example of how modern platforms are evolving to better support code analysis and indexing.
Future of LSIF
The future of LSIF looks promising as it continues to evolve with contributions from the open-source community and organizations like Sourcegraph. There are several areas where LSIF can be expanded to offer even more powerful features:
- Support for More Languages: While LSIF currently supports several languages, expanding its reach to more programming languages would increase its utility and adoption.
- Enhanced Diagnostics: Improving diagnostic capabilities and adding support for more types of analysis could help developers detect a wider range of issues in their code.
- Advanced Semantic Features: Although semantic indentation is not currently supported, future versions of LSIF might include features that capture deeper insights into the structure and behavior of code, leading to more powerful refactoring tools and better code understanding.
The continued development of LSIF will likely involve collaboration across a wide range of tools, IDEs, and language servers, all working together to create a seamless experience for developers. As a standard, LSIF is well-positioned to play a critical role in the evolution of code analysis and intelligence, offering developers the tools they need to work more efficiently and intelligently.
Conclusion
The Language Server Index Format (LSIF) has proven to be a crucial advancement in the way code is indexed and analyzed across different development environments. By offering a standardized format for code indexing and semantic analysis, LSIF has made it possible to create more powerful and efficient language servers, IDEs, and tools that improve the development workflow. Its open-source nature and wide adoption by major platforms like Sourcegraph and GitHub ensure that LSIF will continue to play an important role in the future of software development.
Whether you are working on small projects or large-scale systems, LSIF has the potential to transform how you navigate, understand, and interact with code, enhancing both the developer experience and the quality of the software produced. As LSIF continues to evolve, it will undoubtedly help shape the future of software development in ways that are both exciting and impactful.